უპირველეს ყოვლისა, რომელი არის ყველაზე მარტივი გზა იმისა, რომ მოვახდინოთ კოლიზია HashMap-ში ? შევქმნათ კლასი, რომელსაც ექნება თავისი hash ფუნქცია და დავწეროთ მისი ყველაზე ცუდი იმპლემენტაცია (hashCode მეთოდის). ამის ერთ-ერთი მაგალითია ის, რომ hashCode() მეთოდმა ყოველთვის დააბრუნოს რაიმე კონსტანტა. როგორ ფიქრობთ რა მოხდება ამ დროს ? ტექნიკურ ინტერვიებზე ამ კითხვაზე ხშირად პასუხობენ, რომ ყოველი ახალი ჩამატებული ელემენტი HashMap-ში შეცვლის ძველს, რაც სიმართლეს არ შეესაბამება. Hash Collision არ გულისხმობს იმას, რომ HashMap-ში მონაცემები ერთმანეთს გადაეწერება, ეს ხდება მაშინ და მხოლოდ მაშინ როცა ისეთი ორი ელემენტის ჩასმას ვცდილობთ HashMap-ში, რომელთა Key-ები ტოლია equals() მეთოდზე დაყრდნობით, ანუ equals() მეთოდი აბრუნებს true-ს. ელემენტები არა ტოლი გასაღებებით და ერთნაირი hashCode-ებით მოთავსდება ერთსა და იმავე bucket-ში რომელიღაც ტიპის მონაცემთა სტრუქტურაში (შესამჩნევია რომ ამ შემთხვევაში map-ის საერთო performance გაუარესდება, რადგან ელემენტის ჩასმაც და წაკითხვაც უფრო დიდ დროს წაიღებს).
დასაწყისისთვის მოვიყვანოთ პატარა მაგალითი, რომელიც რა თქმა უნდა, გაზვიადებულია და პრაქტიკაში ნაკლებათ მოსახდენია (თუ საერთოდ მოხდა), მაგრამ ეს მაგალითი კარგად დაგვანახებს განსხვავებას. ამ მაგალითში, კოლიზიები იმაზე მეტი იქნება, ვიდრე ეს რეალურად პრაქტიკაში მოხდება.
მაგალითში, Person ტიპის ობიექტი გვქონდეს HashMap-ის გასაღებად, ხოლო მნიშვნელობები იყოს String.

ახლა კი მოვახდინოთ კოლიზია.
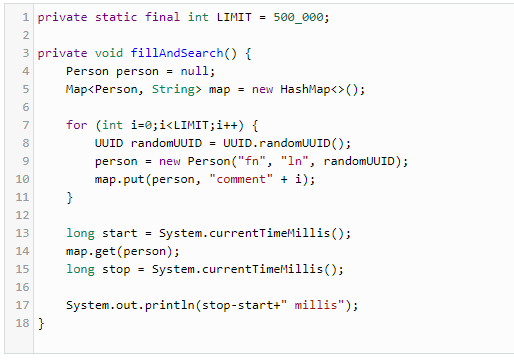
ამ კოდმა საკმაოდ მძლავრ კომპიუტერზე მუშაობას მოანდომა 2.5 საათი და საბოლოოდ ელემენტის წაკითხვამ კი დაახლოებით 40 მილიწამი. ახლა, ყოველგვარი წინასწარი ახნის გარეშე მოდით მოვახდინოთ Peron კლასის მცირე ცვლილება, მოდით მან იმპლემენტაცია გაუკეთოს Comparable<Person> ინტერფეისს და Person კლასში დავამატოთ კოდის შემდეგი ფრაგმენტი

ზემოთ აღნიშნულმა კოდმა, იმავე კომპიუტერზე, მუშაობას მოანდომა ერთ წუთზე ნაკლები და საბოლოოდ ელემენტის წაკითხვას 1 მილიწამი - ანუ ის 150-ჯერ სწრაფად მუშაობს ამ შემთხვევაში.
მოდით ახლა ავხსნათ რა მოხდა. როგორც დასაწყისში აღვნიშნეთ, Java 8-ში წინა ვერსიებთან შედარებით ბევრი კლასი გაუმჯობესდა. Java 7-ში კოლიზირებული (ერთი და იმავე hashCode-ის მქონე ელემენტები) ინახებოდა bucket-ში რომლის სტრუქტურაც იყო LinkedList. Java 8-დან დაწყებული, თუ კოლიზირებული ელემენტების რიცხვი არის გარკვეულ რიცხვზე მეტი (ეს რიცხვი არის 8), და Map-ის capacity არის 64-ზე მეტი, მაშინ HashMap-ის იმპლემენტაცია LinkedList-ის ნაცვლად იქნება BinaryTree.
აქ გაგვიჩნდება აზრი, რომ non-comparable გასაღებების შემთხვევაში, ეს ხე იქნება არაბალანსირებული, მაშინ როცა სხვა შემთხვევაში ის იქნება მეტ-ნაკლებად ბალანსირებული. მაგრამ ეს არ შეესაბამება სიმართლეს. Tree-ის იმპლემენტაცია HashMap-ში არის Red-Black Tree, რაც იმას ნიშნავს, რომ ის ყოველთვის არის ბალანსირებული. თუ ჩვენ დავწერთ utility კლასს, რომელიც ზემთ აღნიშნული მაგალითისთვის შეამოწმებს ხის სიღრმეს, ის იქნება 19.
ახლა მთავარი კითხვა, როგორ მივიღეთ ასეთი დიდი განსხვავება Comparable ინტერფესისის იმპლემენტაციით ? როცა HashMap ცდილობს იპოვოს ხეში ახალი ელემენტისთვის ადგილი, ის ამოწმებს ახალი და ძველი ელემენტები (უკვე არსებული) არის თუ არა ადვილად სადარი (Comparable interface). ჩვენი მაგალითის პირველ შემთხვევაში ის იძახებს tieBreakOrder(Object a, Object b) მეთოდს. ეს მეთოდი პირველად ცდილობს ობიექტების შედარებას class name-ზე დაყრდნობით, და შემდეგ იყენებს System.identityHashCode-ს. მაგრამ, როცა გასაღები აიმპლემენტირებს Comparable-ს ეს პროესი გაცილებით მარტივია. გასაღები (key), თვითონვე განსაზღვრავს როგორ უნდა შეედაროს სხვა ელემენტს და ელემენტის ჩამატება და წაკითხვა უფრო სწრაფად ხდება. tieBreakOrder(Object a, Object b) მეთოდის გამოძახება ხდება მხოლოდ მაშინ თუ ორი ელემენტის compareTo მეთოდი დააბრუნებს 0-ს (ანუ თუ ტოლია).
რომ შევაჯამოთ, Java 8-ში, თუ HashMap-ის bucket-ში ელემენტების რიცხვა გადააჭარბა 8-ს და HashMap-ის ზომამ 64-ს, მაშინ bucket-ის იმპლემენტაცია LinkedList-ის ნაცვლად იქნება Red-Black Tree, რომელიც ყოველთვის დაბალანსებულია და თუ Map-ის გასაღები აიმპლემენტირებს Comparable-ს, მაშინ ელემენტის ჩამატება და წაკითხვა იქნება გაცილებით სწრაფი. მაგრამ უნდა აღინიშნოს ისიც, რომ თუ კოლიზიების რიცხვი არც ისე დიდია, Comparable/ non-Comparable იდეას უკვე დიდი აზრი აღარ აქვს.